

This blog post is written by Jiri Hana, Co-founder of Geneea. Geenea is a certified technology partner to Stibo DX and the Cue media enterprise platform, and a language AI company that turns text into insight. Geneea helps media enterprises automate content analysis, generate summaries, and extract meaning using cutting-edge natural language processing.

Managing fast-moving stories, vast archives, and constant updates is part of daily life for modern publishers. However, connecting that material in a meaningful, reusable way is far harder than it looks.
That’s where semantic tagging offers a practical path forward. By assigning structured tags that describe the essence of the content—people, places, topics, and relationships—it adds context and intelligence in a compact, manageable form. The result is content that is easier to connect, discover, analyze, and reuse across editorial, product, and commercial workflows.
Data-Driven editorial insights
In a high-pressure newsroom, it is nearly impossible to manually track coverage patterns across thousands of articles, podcasts, and videos. Yet, editors and product owners must ensure their output aligns with their broader editorial strategy. Without structured metadata, these discussions often rely on intuition rather than evidence.
Semantic tagging transforms stories into quantifiable data points, providing the analytics necessary to answer questions such as:
- Which topics dominated our coverage this quarter?
- Which geographical regions are underrepresented?
- Is our coverage of political parties proportionate?
- What is the gender ratio of the artists we cover?
- Which companies appear primarily in “crisis” coverage versus “innovation” coverage?
By converting published content into structured data, newsrooms move beyond gut feeling to data-informed, strategic reporting.
Standardized concepts
For these insights to be reliable, tagging must be consistent across the entire archive. If one article is tagged “USA” and another “United States,” the data becomes fragmented and analytics become misleading.
High-quality tagging ensures that every mention refers to a single, unique concept. In practice, this requires a knowledge base that assigns a unique identifier (ID) to each entity and topic. This approach also bridges language barriers: “United States,” “Vereinigte Staaten,” and “Estados Unidos” all refer to the same concept, with the same ID.
The challenge of disambiguation
Unique IDs are only half the battle; the real difficulty lies in contextual disambiguation. When “the Greens” form a coalition in Berlin, they are a distinct entity from Green parties holding press conferences in Vienna, Prague, or Dublin. A robust knowledge base understands the relationships between the German Greens, the country of Germany, and specific politicians, distinguishing them from their international counterparts.
Maintaining this precision requires constant effort. Politicians change roles, parties merge, and new entities emerge daily. An accurate knowledge base depends on continuous updates, automated monitoring, and regular quality checks—an investment often underestimated when teams consider building tagging systems in-house.
Rich tags enable richer use cases
Tags become far more valuable when they connect to external standards. Linking tags to widely used identifiers like Wikidata IDs for entities or IPTC Media Topics for subject classification allows publishers to enrich their own data with external information.
For example, analytics teams can pull in background data about an athlete, a corporation, or a film without manually maintaining those attributes themselves.
Tags across the organization
While editorial insights shape coverage, tags serve as the technical backbone for several other core functions:
- Content Reuse: Richer metadata allows newsrooms to build dynamic topic pages, assemble story packages, refresh evergreen content, and surface background material with minimal manual searching.
- Personalization: Effective personalization requires hybrid systems that combine content-based filtering with collaborative filtering. This balance allows popular content to surface while respecting individual niche interests, introducing novelty and reducing the risk of “filter bubbles”. While off-the-shelf embeddings are a good start, semantic tags significantly improve the quality of the content-based filtering component.
- Contextual Advertising: As privacy shifts limit behavioral targeting, semantic tags provide a viable alternative, allowing advertisers to align their campaigns with relevant content. Combining standard semantic tags with brand-safety categories ensures ads appear in contexts that are both topically relevant and safe.
- SEO: Search engines favor structured metadata and well-interconnected websites.
- Search and RAG: Rich metadata significantly improves Retrieval-Augmented Generation (RAG) and search systems by narrowing the candidate set of relevant articles, either through explicit user filters or automatic selection. This is crucial for large archives where pure vector embeddings may struggle to distinguish between similar content.
- Reader Engagement: Subscribable topic pages, meaningful personalization, and better search and navigation all contribute to a stronger reader experience.
For example, analytics teams can pull in background data about an athlete, a corporation, or a film without manually maintaining those attributes themselves.
Manual tagging – a dead end
At the volume major publishers produce today, relying solely on manual tagging is unsustainable. It is rarely the best use of a journalist’s time and inevitably leads to poor data quality.
When humans tag, inconsistency is all but guaranteed. Part of this is the pressure of the newsroom, but much of it is simple subjectivity. Even without a deadline, different people rarely categorize the world in exactly the same way. One reporter might tag a story “US Politics,” another “White House,” and a third might skip tagging entirely because the article is short. To track trends accurately, publishers need a guarantee that every mention is captured. Automated and hybrid workflows address this, provided they recognize that tags serve two distinct audiences: readers and analysts.
One article, two audiences, two tagging workflows
Tagging for readers: precision and editorial control
Readers and search engines value clarity. They need a small number of clearly relevant tags that help them navigate or decide what to read next. In this context, a wrong tag is an embarrassment, but readers are less concerned with whether tags are applied with perfect consistency across a ten-year archive.
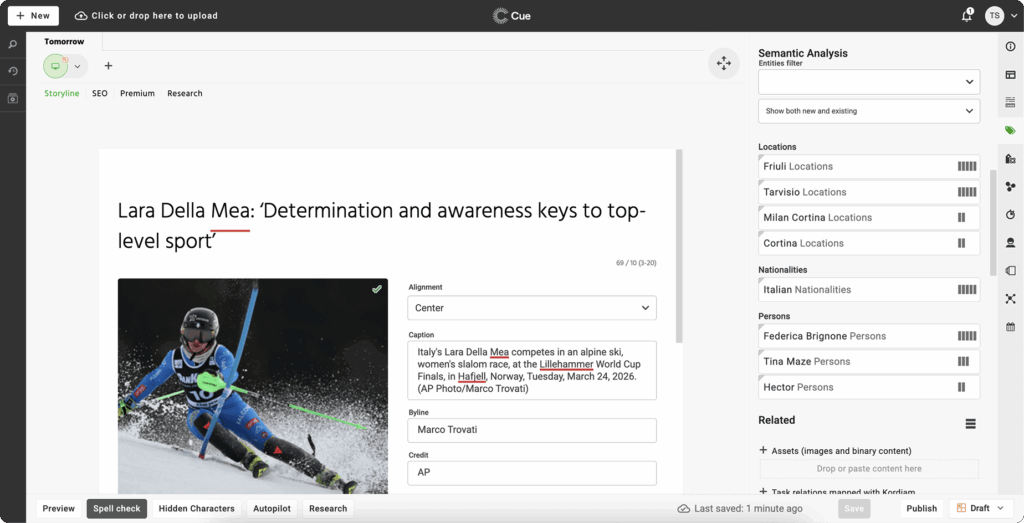
This workflow thrives best with human-in-the-loop supervision. In the Cue Content Store, for instance, the Geneea integration suggests relevant tags, allowing the journalist to quickly review and accept them.
Tagging for analysts: consistency and completeness
Analytics teams have almost the opposite requirement. To track long-term trends, they need high inclusion consistency: if a concept is mentioned, it must be tagged every time. If an automated system misses a tag in 20% of articles, or if a human decides a mention was “too minor” to tag, the resulting dataset becomes unreliable for trend mapping. Analysts can tolerate some noise in exchange for a complete picture.
This is also where relevancy scores become essential. Not all tags are equally important. Analysts need to distinguish between a story about France and a story that merely mentions the country in passing. Relying on a simple count of mentions is often misleading:
- A long feature on some historical topic might mention the country five times but only as a side note.
- Conversely, an article about various French regions won’t repeat the word “France” in every sentence.
Taggers need to look beyond keyword frequency to determine the central theme, assigning a relevancy score, shown as the 1-to-5 bar rating in Cue CS.
This workflow should be fully automated. No human editor has the time to tag every minor entity or map content to IPTC Media Topics for every asset. Cue Dam supports this by applying fully automatic tagging to all incoming assets. A high-quality tagger ensures accuracy, while full automation guarantees that the data remains consistent across the entire archive.
Who needs to be involved?
Successful implementation is rarely a solo project. It typically involves:
- Taxonomy & Metadata Specialists: Someone must maintain controlled vocabularies, add new entities, and monitor disambiguation quality. For many publishers, outsourcing this ongoing work is more efficient than building a permanent internal team.
- Editorial Teams: Editors define which topics matter and ensure that tagging aligns with newsroom language and standards. Their role is strategic guidance, not manual data entry.
- Engineering: Engineers integrate the tagging service into the CMS and Dam. For users of the Cue platform, this integration is already built-in, significantly reducing the technical lift.
- Product, Analytics & Commercial Teams: These are the ultimate consumers of the metadata. Product teams use tags to drive personalization and search features; analytics teams measure content impact; and commercial teams use the data for contextual ad targeting.
How to get started
A practical implementation path typically includes four steps:
1. Define your taxonomy strategy
A controlled vocabulary is essential—tags must be consistent to be useful.
- Standardize where possible: Mapping tags to external standards such as Wikidata or IPTC Media Topics simplifies integration with other systems.
- Plan for custom entities: Most standard databases (like Wikidata) are great for global celebrities but less so for local news. Your system needs to handle local politicians, regional athletes, and emerging businesses that don’t have a Wikipedia page yet.
2. Decide: Build vs. Buy
Building a tagger in-house often seems tempting. The long-term cost lies in maintenance. An in-house solution requires a permanent team just to keep the knowledge base current as the world changes.
But can’t we just use an LLM? Many publishers ask whether LLMs can replace dedicated tagging systems. While powerful, LLMs struggle with two core requirements of tagging:
- Naming consistency: LLMs are creative, which is bad for taxonomy. One day they might tag a story “United States,” the next day “USA,” and the next “America”. Unless constrained by stable identifiers, the data becomes fragmented.
- Relevancy consistency: Even with detailed instructions, LLMs tend to vary in how they judge importance across articles.
The most reliable approach is usually a specialized semantic tagger that uses LLMs for context understanding and quality control but relies on a structured knowledge base for entity assignment and a stable relevancy formula. For most publishers, relying on a specialized partner to handle this “data plumbing” is more sustainable, allowing internal teams to focus on building features with the data rather than maintaining the data itself.
3. Integrate into everyday workflows
Tags should be generated or reviewed inside the CMS and Dam so they become a natural part of production. If you are using Cue, this step is largely solved, supporting both the supervised and automated workflows described above.
- Downstream Integration: Remember to plan for how this data flows to dashboards, personalization engines, and ad inventory tools.
4. Handle archive tagging pragmatically
Most publishers have years—or decades—of archived content. How that archive is handled has a significant impact on the value of semantic tagging, but there is rarely a single “correct” approach. The right strategy depends on editorial goals, available resources, and how the archive is currently used.
For untagged archives: The most straightforward approach is fully automated tagging. This provides consistency and makes historical content searchable, analyzable, and reusable without manual effort. While older content may not require the same level of precision as breaking news, consistent tagging still unlocks long-term value for analytics, search, and personalization.
For already tagged archives: This is more complicated. Several strategies are common:
- Option A: Tag only new content. Simple and inexpensive, but results in fragmented metadata where older and newer content use different naming conventions or levels of granularity, limiting the usefulness of topic pages, analytics, and SEO over time.
- Option B: Retag everything. Produces a clean, consistent result, but may disrupt existing topic pages that have accumulated SEO authority, which needs to be handled carefully.
- Option C: Align and Retag. Map all old tags to the new taxonomy and then retag, adding redirects from old topic pages where needed. With this option, publishers gain consistent metadata while maintaining continuity for readers and search engines. The trade-off is higher upfront effort, as historical tags are often noisy and require some level of supervision to interpret correctly.
- Option D: Align High-Value Tags (Recommended). In most manually tagged archives, a large proportion of tags are used only a handful of times. Prioritizing frequently used or high-value tags allows publishers to capture most of the benefit while keeping costs and complexity under control.
An example of these principles in practice
To make this more concrete, let’s look at how Geneea’s tagging system implements these ideas within the Cue environment:
- A continuously maintained knowledge base: Entities and topics are monitored and updated as the world changes, rather than treated as a static dictionary.
- Context-aware disambiguation: The system distinguishes between people, organizations, or products with the same name based on relationships and context.
- Stable external identifiers: Tags are linked to standards such as Wikidata IDs for entities and IPTC Media Topics for subject classification, making it easier to connect content with external datasets.
- Support for custom entities: The system handles local politicians and regional organizations central to local journalism that may not have Wikipedia pages.
Maintaining quality relies on a combination of approaches:
- Continuous synchronization with external sources (Wikidata, stock exchanges, official registers) to reflect structural changes in the real world.
- Automated monitoring and quality checks, including the use of LLMs to flag potential inconsistencies or questionable disambiguations.
- Human supervision by data analysts who review edge cases, validate new entity types, and refine disambiguation rules.
- Analysis of customer-provided corrections.
The tagger is integrated directly into the Cue Platform, supporting both supervised editorial workflows in Cue Content Store and fully automated tagging in Cue Dam.
Final thoughts
Semantic tagging helps publishers extract far more value from every piece of content they produce. It turns stories into structured data, enabling publishers to serve audiences better, understand coverage more clearly, and unlock new commercial and editorial possibilities.
As news organizations continue to scale output and adopt AI-driven operations, semantic tagging becomes foundational infrastructure rather than a side feature. It supports smarter search, deeper analytics, better personalization, balanced coverage, and more efficient workflows—all essential for digital publishing success.